
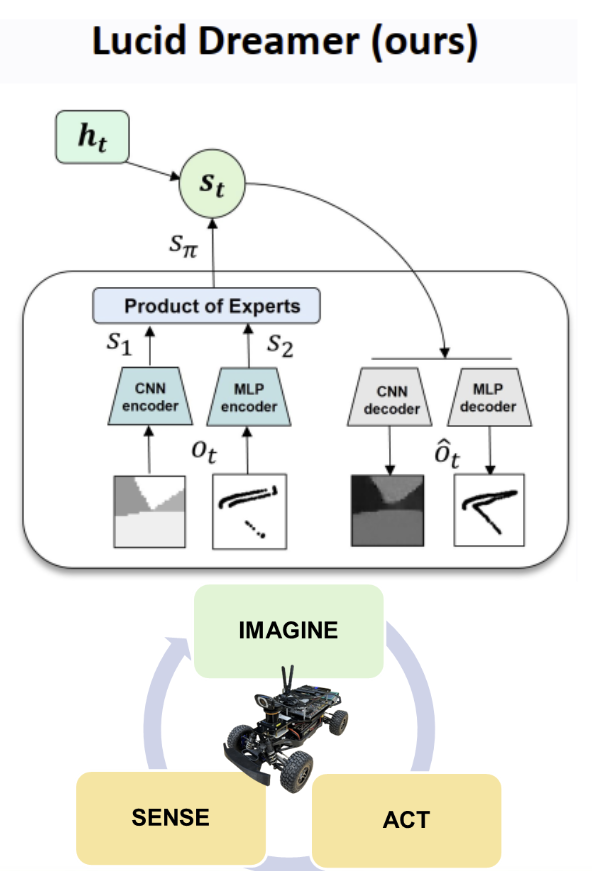
Lucid Dreamer: Multimodal World Model for Zero-Shot Policy Transfer in Multi-Agent Autonomous Racing
Published:
Brief: While reinforcement learning offers potential for continual learning and adaptability in complex scenarios, its application to real-world robotics faces significant challenges. Unlike in simulations, physical platforms struggle to collect a diverse corpus of training data due to critical safety risks and the inherent constraints of operating within a dynamic and partially observable environment. Our work draws inspiration from the human capability to fuse and exploit multiple sensing modalities, construct comprehensive models of how the world operates, and then leverage those models to adeptly navigate in challenging and often unpredictable environments. Here is an overview of how unmanned vehicles (ground, air, and surface) can exploit a world model constructed through multimodal perception, to learn near-optimal policies for guidance and control. A key aspect of the approach is learning from imagination in which the world model is used to simulate future imagined trajectories, enabling it to anticipate potential risks before encountering them in the real world. Our ongoing work and long-term vision is to evolve the traditional sense-plan-act framework into a more intuitive and cognitively inspired sense-imagine-act model. Dr. Elena Shrestha's presentation of our research.
Role: Graduate Research Assistant, Robotics & Optimization for Analysis of Human Motion (ROAHM) Lab
Autonomous Racing Challenges:
- Difficult to collecting realistic training data
- Noisy sensor measurements
- Model uncertainty (dynamics)
- Reduced performance and reliability
- Real-time decision-making is essential
- The limitations of onboard hardware
- Complex, unstructured environments
- Stochastic nature of environment
- Localization and mapping

Goal: This project aims to overcome these obstacles, enabling the successful deployment and operation of AV in unpredictable environments, using our MBRL model.
Why Model-based Reinforcement Learning (MBRL)?
- Better Adaptation: Learns an internal model of the environment, helping it adapt to new policies and conditions, unlike model-free RL, which relies only on previous experience.
- Faster Learning: Learns efficiently with fewer interactions than model-free RL, saving time and reducing the need for costly or risky data collection.
- Clearer Decisions: Tracks important details about the environment, making it easier to understand and improve the agent’s behavior.
- Stronger Sensor Integration: Combines inputs from multiple sensors (like LiDAR and cameras), giving a more accurate view of surroundings.
- Safer High-Speed Control: Plans actions with an awareness of dynamics, balancing speed with safety, ideal for real-time sudden scenarios.
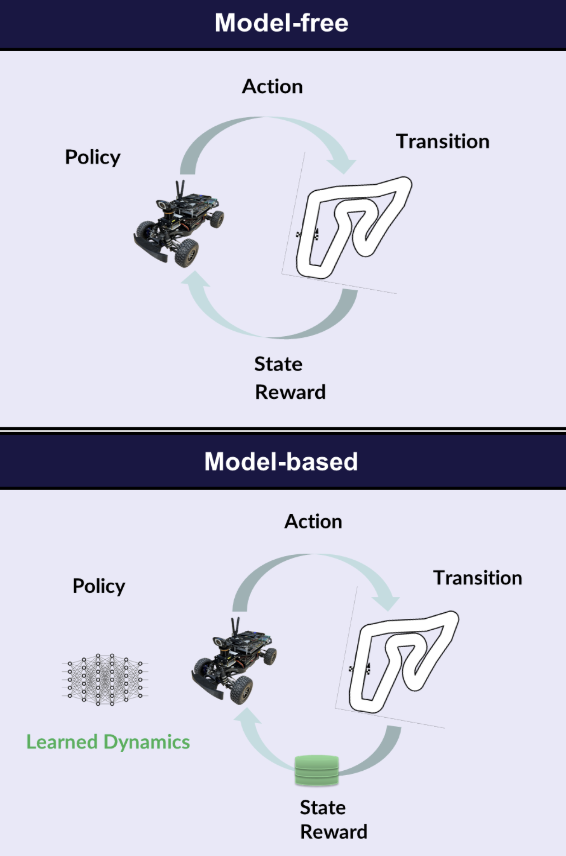
Related Work in MBRL for AV Path Planning

Our MBRL for USV Path Planning
Method:
- Adaptive Model Predictive Control (MPC): Dynamically adjusts to environmental changes using probabilistic models.
- Online Learning: Incorporates new data in real-time to improve model accuracy and robustness.
- Efficiency-Focused Design: Optimizes control actions to minimize computation while maintaining high control stability.
Key Results:
- Fast adaptation in dynamic conditions with reduced model drift.
- High reliability in trajectory tracking and position-keeping under varying disturbances.
Hardware/System Design
- IMU
- RGB Camera
- LIDAR
- Onboard Linux computer
- Battery
- Motor Controller

My Contribution: Worked on “Lucid Dreamer: Multimodal World Model for Zero-Shot Policy Transfer in Multi-Agent Autonomous Racing” as the third author
- Prepared and maintained robot hardware for real-world testing by assembling batteries, mechanical components, and sensors (LiDAR, camera, IMU, odometry), ensuring seamless data integration and system functionality.
- Implemented SLAM using ROS packages, resolved frame transformation issues, and calibrated IMUs to improve system reliability and localization accuracy in dynamic environments for future tests.
- Designed and implemented a waypoint-follower algorithm in ROS for benchmarking Lucid Dreamer, enabling precise navigation and path planning in multi-agent reinforcement learning experiments.
- Collected and analyzed sensor data during real-world tests to enhance reinforcement learning models, improving the robot’s autonomous navigation and control in dynamic scenarios.
- Optimized Jetson TX2 performance for real-time processing, reducing semantic segmentation latency and ensuring efficient operation in resource-constrained environments.
Summary
- This project aims to develop an adaptive, real-time control system for autonomous racing system of AV.
- Using Model-Based Reinforcement Learning (MBRL), the project addresses key challenges such as variable environmental conditions, sensor noise, and model uncertainty.
- Through innovations in adaptive model predictive control, real-time online learning, and sensor fusion, the system aims to enable reliable autonomous racing decision under unpredictable conditions while minimizing computational load.
- Real-world testing supports the system’s stability, demonstrating effective safety and collision avoidance in racing track.
Future Work
- Improve the model to work on higher complex environment.
- Update the dimension/measurement of each sensor location to be more accurate for better result.
- Improve the waypoint-following algorithm.
- Update the simulation environment to be more realistic.
- Fix camera’s URDF configuration in the code for future need.
[GitHub][Publication][Slide]
Skills: ROS, Rviz, Gazebo, PyTorch, TensorFlow, U-Net, OpenCV, Python, C++, Linux, Bash/Shell Scripting, Git, Docker, Microcontroller, SolidWorks, 3D printing
Contributors' Acknowledgement: Prof. Ram Vasudevan, Dr. Elena Shrestha, Hanxi Wan, Madhav Rawal, Surya Singh